Rhythms of the
language
Alphabets,
syllabaries,
idiographies – the choice of a writing system may be influenced by a
language’s
cadence.
The choice of how a
language
invents a Pig Latin may as well. [1]
[2]
A language like
Hawaiian (like Cherokee and Inupiaq) would be well
suited for the development of a syllabary, instead of an alphabet.
Why?: agglutination (rather than inflection or isolation) few
consonants and even fewer consonant clusters.
Consider the
following:
forty 5
ghost 5
gipsy 5
glory 5
mopsy 5
almost 6
begirt 6
biopsy 6
chintz 6
dehort 6
What do they have in common?
Or... how about these?:
inkier
and purply (hint:
,5,-3,-2,-4,13)
Outline:
About
letters in alphabetical or inverse alphbetical order
Letters
in alphabetical or inverse alphbetical order : Examples
formalisms
and probabilities
Rhythms
of alphabetic ordering for
artificial and actual words
Words
of a given rhythm
Letter
gap differentials
A
different kind of rhyme: Words with rhyming gap differentials
More
"standard" (acoustically obvious) rhythms
Dividing
characters into
Consonants and Vowels
Consononant
Vowel rhythms in English, Spanish, French and German vocabulary
pretty
picture
space
On
probabiliities of monotonic
(and other) letter sequences:
Motivation: there are
more words
whose letters are in alphabetical order than whose letters are in
inverse
alphabetical order:
#(alpha order)
$ cat $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i <
$(i+1)) c++ }; if
(c>NF-2) print $0,NF }' FS=""|sort -nk2|wc
212
424
1362
#(inverse alpha order)
$ cat $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i >
$(i+1)) c++ }; if
(c>NF-1) print $0,NF }' FS=""|sort -nk2|wc
145
290
914
Examples:
| $
cat $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i <
$(i+1)) c++ }; if
(c>NF-2) print $0,NF }' FS=""|sort -nk2|tail |
$
cat $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i >
$(i+1)) c++ }; if
(c>NF-1) print $0,NF }' FS=""|sort -nk2|tail |
forty
5
ghost 5
gipsy 5
glory 5
mopsy 5
almost 6
begirt 6
biopsy 6
chintz 6
dehort 6 |
polka
5
solid 5
sonic 5
spoke 5
theca 5
tonic 5
unfed 5
wrong 5
sponge 6
vomica 6 |
This observation led to an investigation of “lexical letter rhythms,” as well as curiosity about
a) whether the above
points to some “preference” of monotonically
increasing
sequences, or simply to the possibility that more English words begin
with
letters early in the alphabet, hence making increasing sequences more
probably
b) whether the rhythms of
monotonicity in letter sequences favor certain patterns more than others
c) the extent to which all of this
can be explained by pure randomness.
Let α∈ {a..z}* with |α|=2
and α =a1a2.
(In English, this just means let the symbol alpha refer to a string of
two lowercase letters (a1 and a2) from the
English alphabet.)
Let us write a1 < a2
to mean that a1 is alphabetically
prior to a2 .
If α is chosen at random from {a..z}*, then P(a1
= a2) = 1/26
and P(a1 < a2)= ½
(25/26) ≈ .48 .
In actuality, of the 43 two letter words in w$:
$ egrep ^[a-z]{2}$ $w
ah
am
an
as
at |
ax
ay
be
bo
by |
do
em
en
ex
fa |
go
ha
he
id
if |
in
is
it
la
lo |
me
mi
my
no
of |
oh
on
or
os
ox |
pi
re
so
to
up |
us
we
ye |
$ egrep ^[a-z]{2}$ $w|wc
43
43 129
24 of them have a1 < a2, while the other 19 have a1
> a2
. This is not likely outside the expectations of chance.
For longer words, though, the situation is more complex. Let’s consider
three letter sequences, both English words and nonwords.
For arbitrary letter sequences , α∈ {a..z}* with |α|=2
and α
=a1a2 … an ,we call a
letter sequence monotonic increasing if ai
< aj for all i and j less than
n+1. It is monotonic
nondecreasing if ∀ i,j ai ≤ aj
.
Examples:
- α =abc is monotonic increasing, but is not a word.
- his is a monotonic increasing word.
- accent is a nondecreasing word
- zone is a decreasing word.
- yucca is a nonincreasing word.
Rhythms of alphabetic ordering
for artificial and actual words
-----------------------
Four letter words
-- what are the most common rhythms?
sampling real words:
$ egrep ^.{4}$ $w|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq
-cf1|sort –n
sampling artificial sequences
$ shuf -ern 8000 {a..z}|xargs -L 4|sed 's/\ //g'|awk '{for
(i=1;i<NF;i++) {if ($i>$(i+1))s=s""0;else if
($i<$(i+1))s=s""2;else s=s""1};{print s" "$0;s="";}} ' FS=""|awk
'{print $2,$1}'|sort -k2|uniq -cf1|sort -n|tail -18
10 blls
212 1 eery 122
11 bbcz
122 1 ooze 120
11 hhfd
100 8 miff 001
16 agqq
221 19 bell 221
18 dccx
012 21 ally 212
22 aame
120 23 feed 010
24 ddbx
102 27 abba 210
25 ajjh
210 38 eddy 012
25 cabb
021 39 biff 201
28 amhh
201 47 ball 021
64 abcy
222 50 life 000
72 hfea
000 63 abet 222
197 bafn
022 174 able 220
205 ecbd
002 190 aged 200
206 abqj
220 202 fear 002
222 amja
200 248 babe 022
408 bazq
020 365 afar 202
417 aeaf
202 475 bake 020
The above data
represent rhythm frequencies, example words, and actual
rhythm patterns
Down up down (020) as in the word "bake" is most frequent (475 out of
the 1991 four letter words in this resource (FRELI))
Second most common rhythm pattern, 202, as in "afar" with this rhythm
present in 365 of the words.
Six letter words,
(imaginary and real), and example rhythms
$ paste <(shuf -ern 25000 {a..z}|xargs -L 6|sed 's/\ //g'|awk
'{for (i=1;i<NF;i++) {if ($i>$(i+1))s=s""0;else if
($i<$(i+1))s=s""2;else s=s""1};{print s" "$0;s="";}} ' FS=""|awk
'{print $2,$1}'|sort -k2|uniq -cf1|sort -n|tail -20) <(egrep
^.{6}$ $w|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq
-cf1|sort -n|tail -20)
64 gazfec
02000 65 adagio 20222
70 acadpw
20222 66 health 00220
78 aglbgo
22022 67 backup 02220
78 awgfck
20002 69 abduce 22202
90 ihcxut
00200 101 amical 20002
101 dabnxd
02220 108 abrade 22022
115 atrauv
20022 108 cajole 02200
122 bamuih
02200 109 ballad 02102
124 abriet
22002 134 abased 20200
153 ebaltp
00220 146 abacus 20220
157 bahehv
02022 148 abject 22002
169 abnfwk
22020 148 alight 20022
171 akauob
20200 176 ablate 22020
189 asnlol
20020 181 afeard 20020
193 baqrbe
02202 183 featly 00202
199 gdayfp
00202 237 backer 02202
213 acadvq
20220 254 bakery 02022
231 caztov
02002 270 banger 02002
293 cawlnc
02020 317 agency 20202
304 abapcl
20202 346 balize 02020
words
of a given rhythm
02102 (ballad)
Compare its frequency (109 words out of 4321 six letter words) with the
following based on a similar count ($ echo "4321 * 6"|bc = 25926) of
six letter random words:
$ shuf -ern 25926 {a..z}|xargs -L 6|sed 's/\ //g'|awk '{for
(i=1;i<NF;i++) {if ($i>$(i+1))s=s""0;else if
($i<$(i+1))s=s""2;else s=s""1};{print s" "$0;s="";}} ' FS=""|awk
'{print $2,$1}'|sort -k2|uniq -cf1|sort -n|grep 02102
11 ihvviw 02102
Such a rhythm is much more likely in English than in random letter
sequences
Here's how to find all the words of that given rhythm:
$
egrep ^.{6}$ $w|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print
s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|grep 02102|xargs -L6
ballad 02102 ballet 02102 banner 02102 barrel 02102 barren 02102 barrow
02102
basset 02102 batten 02102 batter 02102 caller 02102 capper 02102 carrot
02102
dagger 02102 dapper 02102 fallen 02102 farrow 02102 fatten 02102 fellah
02102
fennel 02102 ferret 02102 fetter 02102 gaffer 02102 galley 02102 gammer
02102
garret 02102 hammer 02102 happen 02102 harrow 02102 hatter 02102 jennet
02102
kennel 02102 killer 02102 kipper 02102 kisser 02102 kitten 02102 lammas
02102
lappet 02102 latter 02102 lerret 02102 lessen 02102 lesser 02102 lessor
02102
letter 02102 litter 02102 mallet 02102 mammal 02102 manner 02102 marrow
02102
matter 02102 miller 02102 millet 02102 mirror 02102 mitten 02102 mizzen
02102
narrow 02102 natter 02102 nipper 02102 pallet 02102 parrot 02102 passim
02102
patten 02102 patter 02102 pellet 02102 pepper 02102 pillar 02102 potter
02102
powwow 02102 rammer 02102 rappel 02102 rattan 02102 reggae 02102 rillet
02102
rotten 02102 rotter 02102 sapper 02102 seller 02102 setter 02102 simmer
02102
sinner 02102 sippet 02102 sirrah 02102 sitter 02102 sorrel 02102 sorrow
02102
tanner 02102 tassel 02102 tatter 02102 teller 02102 tenner 02102 tennis
02102
terret 02102 terror 02102 tetter 02102 tiller 02102 tippet 02102 titter
02102
topper 02102 totter 02102 valley 02102 vassal 02102 vennel 02102 vessel
02102
wallet 02102 warren 02102 winner 02102 yammer 02102 yarrow 02102 zaffer
02102
zipper 02102
Eight letter rhythms:
real and artificial
$ paste <(shuf -ern 41000 {a..z}|xargs -L 8|sed 's/\ //g'|awk
'{for (i=1;i<NF;i++) {if ($i>$(i+1))s=s""0;else if
($i<$(i+1))s=s""2;else s=s""1};{print s" "$0;s="";}} ' FS=""|awk
'{print $2,$1}'|sort -k2|uniq -cf1|sort -n|tail -20) <(egrep
^.{8}$ $w|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq
-cf1|sort -n|tail -20)
59 cayeaeyh
0200220 59 apiarian 2002002
60 ageamwpu
2002202 61 abjectly 2200202
63 hdauctlc
0020200 63 babushka 0220020
64 ajcbsdsy
2002022 64 alarmist 2020022
65 cbfyfrsk
0220220 66 headland 0022020
67 abvpdzst
2200202 71 backdrop 0220202
69 afbudzfa
2020200 74 alacrity 2022022
75 ihaqpvuy
0020202 75 amenable 2020220
76 dbdcprnw
0202202 87 barbican 0202002
78 dcogogep
0202002 90 balister 0202202
81 acobrqsf
2202020 91 alkahest 2002022
82 ajfocfrp
2020220 93 acarpous 2020020
86 agcfxhvb
2022020 93 bargeman 0200202
87 baqnclkx
0200202 102 actively 2202022
91 canjpghr
0202022 123 acanthus 2022020
94 ajedfewl
2002020 132 ablation 2202020
94 aoevpozg
2020020 135 bakeshop 0202022
100 baetkvdp
0220202 139 alfresco 2020202
154 dcectqxe
0202020 145 alienage 2002020
166 ajgteico
2020202 227 balanced 0202020
Letter
gap differentials
$ egrep ^.{4}$ $w|awk 'BEGIN { C = "" ; for ( i = 0 ; ++i
< 256 ; ) C = C sprintf ( "%c" , i ) };{for
(i=1;i<NF;i++) {s=s"."(index(C,$(i+1))-index(C,$i))};{print s"
"$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq -cf1|sort -n|tail
-20
2 hide .1.-5.1
2 john .5.-7.6
2 lean .-7.-4.13
2 link .-3.5.-3
2 lion .-3.6.-1
2 loaf .3.-14.5
2 loch .3.-12.5
2 meed .-8.0.-1
2 milt .-4.3.8
2 mold .2.-3.-8
2 molt .2.-3.8
2 opal .1.-15.11
2 open .1.-11.9
2 pail .-15.8.3
2 pelt .-11.7.8
2 proa .2.-3.-14
2 punk .5.-7.-3
2 spec .-3.-11.-2
3 abba .1.0.-1
3 lang .-11.13.-7
$ egrep ^.{4}$ $w|awk 'BEGIN { C = "" ; for ( i = 0 ; ++i
< 256 ; ) C = C sprintf ( "%c" , i ) };{for
(i=1;i<NF;i++) {s=s"."(index(C,$(i+1))-index(C,$i))};{print s"
"$0;s="";}} ' FS=""|awk '{print $2,$1}'|grep 1.0.-1
abba deed noon.1.0.-1
lang perk shun.-11.13.-7
$ egrep ^.{3}$ $w|awk 'BEGIN { C = "" ; for ( i = 0 ; ++i
< 256 ; ) C = C sprintf ( "%c" , i ) };{for
(i=1;i<NF;i++) {s=s"."(index(C,$(i+1))-index(C,$i))};{print s"
"$0;s="";}} ' FS=""|awk '{print $2,$1}'|grep "\.3\.0"
add bee ill loo.3.0
$ egrep ^.{5}$ $w|awk 'BEGIN { C = "" ; for ( i = 0 ; ++i
< 256 ; ) C = C sprintf ( "%c" , i ) };{for
(i=1;i<NF;i++) {s=s"."(index(C,$(i+1))-index(C,$i))};{print s"
"$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq -cf1|sort -n|tail
-5
1 zocle .-11.-12.9.-7
2 chain .5.-7.8.5
2 cheer .5.-3.0.13
2 opera .1.-11.13.-17
2 pecan .-11.-2.-2.13
A different kind of rhyme: Words
with rhyming gap differentials
$ egrep ^.{5}$ $w|awk 'BEGIN { C = "" ; for ( i = 0 ; ++i
< 256 ; ) C = C sprintf ( "%c" , i ) };{for
(i=1;i<NF;i++) {s=s"."(index(C,$(i+1))-index(C,$i))};{print s"
"$0;s="";}} ' FS=""|awk '{print $2,$1}'|grep ".-11.-2.-2.13"
Etc. for opera, cheer, chain
pecan tiger .-11.-2.-2.13
opera stive .1.-11.13.-17
cheer jolly .5.-3.0.13
chain ingot .5.-7.8.5
Bigger dictionary ($T)
$ egrep ^.{7}$ $T|awk 'BEGIN { C = "" ; for ( i = 0 ; ++i
< 256 ; ) C = C sprintf ( "%c" , i ) };{for
(i=1;i<NF;i++) {s=s"."(index(C,$(i+1))-index(C,$i))};{print s"
"$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq -cf1|sort -n|tail
-5
1 zymotic
.-1.-12.2.5.-11.-6
1 zymurgy
.-1.-12.8.-3.-11.18
1 zyzzyva
.-1.1.0.-1.-3.-21
2 fortran
.9.3.2.-2.-17.13 (FORTRAN)
2 primero
sulphur.2.-9.4.-8.13.-3
steeds tuffet .1.-15.0.-1.15
paopao testes .-15.14.1.-15.14
inkier purply .5.-3.-2.-4.13
alohas grungy .11.3.-7.-7.18
anteed bouffe .13.6.-15.0.-1
pinot .-7.5.1.5 unsty .-7.5.1.5
mocha .2.-12.5.-7 suing .2.-12.5.-7
labor .-11.1.13.3 shivy .-11.1.13.3
ebola .-3.13.-3.-11 herod .-3.13.-3.-11
cobra .12.-13.16.-17 freud .12.-13.16.-17
banjo .-1.13.-4.5 ferns .-1.13.-4.5
$ egrep ^[a-z]{3}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
< $(i+1)) c++ }; if (c>NF-2) print $0,NF }' FS=""|sort
-nk2|wc
86
172 516
$ egrep ^[a-z]{3}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
< $(i+1)) c++ }; if (c>NF-2) print $0,NF }' FS=""|head
-30|xargs -L10
ace 3 act 3 ado 3 aft 3 ago 3 ail 3 aim 3 air 3 alp 3 amp 3
ant 3 any 3 apt 3 art 3 beg 3 bel 3 ben 3 bet 3 bey 3 bin 3
bis 3 bit 3 biz 3 bow 3 box 3 boy 3 buy 3 cop 3 cot 3 cow 3
Nondecreasing:
threes:
$ egrep ^[a-z]{3}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
<= $(i+1)) c++ }; if (c>NF-2) print $0,NF }' FS=""|wc
102
204 612
(includes, for example, eel, inn and moo that are not strictly
monotonic)
$ echo {a..z}| sed 's/[ ]/*/g;s/z/z*/'
a*b*c*d*e*f*g*h*i*j*k*l*m*n*o*p*q*r*s*t*u*v*w*x*y*z*
$ grep ^`echo {a..z}| sed 's/[ ]/*/g;s/z/z*/'`$ $w|wc
310
310 1496
$ grep ^`echo {a..z}| sed 's/[ ]/*/g;s/z/z*/'`$ $w|xargs -L10|head -5
a abbess abbey abbot abet abhor ably abort accent accept
access accost ace act add adder adept adit ado adopt
aegis affix afflux afoot aft agio aglow ago ah ail
aim air airy all alloquy allot allow alloy ally almost
alms alp am amp amps an annoy ant any apt
Nonincreasing:
$ grep ^`echo {z..a}| sed 's/[ ]/*/g;s/a/a*/'`$ $w|wc
196
196 900
Only 196 of these, as opposed to 310 nondecreasing
$ grep ^`echo {z..a}| sed 's/[ ]/*/g;s/a/a*/'`$ $w|xargs -L10|tail -5
unfed up upon urge urn us use used via vie
void vomica we web wed wee weed wife wig wigged
woe woke wold wolf womb won woo wood woof wool
woon wrong x ye yea yob yoga yoke yolk yon
yucca yule yuppie zone zoo zoom
So, for a random string of length three to be monotonic increasing, we
must have all three chars distinct. Of the 26^3 = 17576 strings of
length three, 26* 25* 24 of them have three distinct chars. So P(3
distinct) = 26*25*24/26^3 ≈ .888. Once three distinct chars are chosen,
each of the six orderings (abc, acb, bac, bca, cab and cba) is equally
likely, and only one is monotonic increasing. Hence the probability of
getting three chars, at random, to be monotonic increasing is about
.148 . The same would be true of the probability of having three chars
being monotonic decreasing.
Given that there are 587 three letter words in $w *, we’d
expect (26*25*24/(6*26^3))*587 or about 86.83 to be monotonic
increasing and the same number to be monotonic decreasing.
Sure enough, there are 86 increasing words:
$ egrep ^[a-z]{3}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
< $(i+1)) c++ }; if (c>NF-2) print $0 }' FS=""|wc
86
86 344
$ egrep ^[a-z]{3}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
< $(i+1)) c++ }; if (c>NF-2) print $0 }' FS=""|tail
-30|xargs -L15
fry gin gnu got guy him hip his hit hop hot how hoy imp ivy
jot joy lop lot low lox loy mop mow nor not now opt pry sty
But only 57 decreasing ones:
$ egrep ^[a-z]{3}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
> $(i+1)) c++ }; if (c>NF-1) print $0 }' FS=""|wc
57
57 228
$ egrep ^[a-z]{3}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
> $(i+1)) c++ }; if (c>NF-1) print $0 }' FS=""|tail
-30|xargs -L15
sec she sib sic ski sob sod son spa tea ted the tic tie tod
toe tom ton urn use via vie web wed wig woe won yea yob yon
* $ egrep ^[a-z]{3}$ $w|wc
587
587 2348
examples:
$ egrep ^[a-z]{3}$ $w|tail -45|xargs -L15
vim vow wad wag wan war was wat wax way web wed wee wem wen
wet who why wig win wit woe won woo wop wot wry yak yam yap
yaw yea yen yes yet yew yin yip yob yon you zap zip zit zoo
Four letter words
For four letters, the probability of four random letters being all
different is
(26*25*24*23/(26^4)) ≈.785 .
Once all four letters are different, the likelihood of being
monotonically increasing would be 1/24 (given 4! permutations of the
letters, with only one of those being as desired).
(26*25*24*23/(26^4))/24≈ .0327.
$ egrep ^[a-z]{4}$ $w|tail -45|xargs
-L15
word wore work worm worn wove wrap wren writ wynd yang yank yard yare
yarn
yarr yaup yawl yawn yawp yean year yell yelp yerk yeti yipe yoga yogi
yoho
yoke yolk yore your yule zany zarp zeal zebu zero zest zinc zone zoom
zoot
$ egrep ^[a-z]{4}$ $w|wc
1953
1953 9765
We would thus, expect about 1953 * .0327≈63.89 of the four letter words
to increase alphabetically.
Sure enough,
$ egrep ^[a-z]{4}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
< $(i+1)) c++ }; if (c>NF-2) print $0 }' FS=""|wc
61
61 305
$ egrep ^[a-z]{4}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
< $(i+1)) c++ }; if (c>NF-2) print $0 }' FS=""|xargs -L16
abet ably adit agio airy alms amps arty belt bent best bevy blot blow
cent chin
chip chit chop chow city clot cloy copy cost cosy crux deft defy demo
dent deny
dewy dint dirt dory doxy envy film fist flop flow flux fort foxy gilt
gimp girt
gist glow gory hilt hint hist hops host knot know lost most nosy
However, again, the reversals seem not to hold up their end of the
probability distribution:
$ egrep ^[a-z]{4}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
> $(i+1)) c++ }; if (c>NF-1) print $0 }' FS=""|wc
48
48 240
$ egrep ^[a-z]{4}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
> $(i+1)) c++ }; if (c>NF-1) print $0 }' FS=""|xargs -L16
life mica olid pica pied plea poke pole pond rife role shed skid sled
slid soda
sofa soke sold sole some song spec sped spic tied toga told tomb tome
tone tong
trig trod upon urge used void wife woke wold wolf womb yoga yoke yolk
yule zone
Five letter words:
$ egrep ^[a-z]{5}$ $w|wc
2892
2892 17352
$ egrep ^[a-z]{5}$ $w|tail -36|xargs
-L12
worth would wound woven wrack wrath wreak wreck wrest wring wrist write
wrong wrote wrung wryly xebec xenia xerox yacht yahoo yamen yearn yeast
yield yodel yokel young yours youth yucca zambo zebra zilch zippo zocle
Increasing:
$ egrep ^[a-z]{5}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
< $(i+1)) c++ }; if (c>NF-2) print $0 }' FS=""|xargs -L12
abhor abort adept adopt aegis aglow befit begin begot below bijou chimp
deist deity dirty empty filmy first forty ghost gipsy glory mopsy
]$ egrep ^[a-z]{5}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
< $(i+1)) c++ }; if (c>NF-2) print $0 }' FS=""|wc
23
23 138
Decreasing:
$ egrep ^[a-z]{5}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
> $(i+1)) c++ }; if (c>NF-1) print $0 }' FS=""|wc
8
8 48
$ egrep ^[a-z]{5}$ $w|awk '{c=0; for (i=1; i<=NF; ++i) { if ($i
> $(i+1)) c++ }; if (c>NF-1) print $0 }' FS=""|xargs -L12
polka solid sonic spoke theca tonic unfed wrong
Expectation:
About 2/3 of 5 letter sequences would have all five letters different:
((26*25*24*23*22/(26^5))) ≈ .6644.
But those 5 letters must all be in the proper order (which happens with
probability only 1/5! or 1/120 )
((26*25*24*23*22/(26^5))/120) ≈ 0.005536
With 2892 five letter words, then we’d expect
((26*25*24*23*22/(26^5))/120)* 2892 ≈ 16.011 for both increasing and
decreasing.
Are variations as wide as 23 (increasing) and 8 (decreasing) within the
realm of randomness?
Here are some random trials. The script generates 14460 chars in 2892
groups of five letter words and then sorts the words based on their
internal rhythms (see more on this topic later). We restrict the output
to the strictly increasing sequences (2222) or the scrictly decreasing
ones (0000). A few trials are run just to give an idea
]$ shuf -ern 14460 {a..z}|xargs -L 5|sed 's/\ //g'|awk '{for
(i=1;i<NF;i++) {if ($i>$(i+1))s=s""0;else if
($i<$(i+1))s=s""2;else s=s""1};{print s" "$0;s="";}} ' FS=""|awk
'{print $2,$1}'|sort -k2|uniq -cf1|sort -n|egrep "([02])\1\1\1"
10 aboqy 2222
15 rkiha 0000
12 nhgcb 0000
18 adkpq 2222
12 aisuw 2222
18 tngfe 0000
11 acfst 2222
23 igfba 0000
13 aglvx 2222
13 jhfea 0000
15 nmjhf 0000
18 acimz 2222
14 mihfa 0000
16 adflr 2222
8 adhtz 2222
18 roidc 0000
2892 * 5 = 14460
Sure enough, variations as wide as observed among real words are seen
as entirely possible within the laws of chance.
Six
((26*25*24*23*22*21/(26^6))) ≈ 0.5366
((26*25*24*23*22*21/(26^6)))/720 ≈ 0.00074528404
$ egrep ^[a-z]{6}$ $w|wc
4278
4278 29946
4278*((26*25*24*23*22*21/(26^6)))/720 ≈ 3.188 = expected number of
monotonic (up or down) sequences for six letter strings.
$ expr 4278 "*" 6
25668
$ shuf -ern 25668 {a..z}|xargs -L 6|sed 's/\ //g'|awk '{for
(i=1;i<NF;i++) {if ($i>$(i+1))s=s""0;else if
($i<$(i+1))s=s""2;else s=s""1};{print s" "$0;s="";}} ' FS=""|awk
'{print $2,$1}'|sort -k2|uniq -cf1|sort -n|egrep "([012])\1\1\1\1"
4 aejkls 22222
5 utokdc 00000
2 abdhrs 22222
3 ysonga 00000
3 abltuv 22222
3 wtoldc 00000
1 eimpqv 22222
2 vupkga 00000
0
00000
2 cefjmy 22222
4 omjfea 00000
6 aekqtx 22222
3 ahmotv 22222
3 toieca 00000
4 pmhgfd 00000
5 adfhln 22222
$ egrep ^[a-z]{6}$ $w|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq
-cf1|sort -n|egrep "([012])\1\1\1\1"
2 sponge 00000
5 almost 22222
Seven
((26*25*24*23*22*21*20/(26^7)))≈ 0.4128
((26*25*24*23*22*21*20/(26^7)))/5040 ≈ 0.0000819
$ egrep ^[a-z]{7}$ $w|wc
4854
4854 38832
4854 *
((26*25*24*23*22*21*20/(26^7)))/5040 ≈ 0.3975= expected
number of monotonic (up or down) sequences for seven letter strings.
$ expr 4278 "*" 6
25668
$ egrep ^[a-z]{7}$ $w|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq
-cf1|sort -n|egrep "([012])\1\1\1\1"
1 dyspnea 200000
2 obloquy 022222
2 polecat 000002
$ egrep ^[a-z]{7}$ $w|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|egrep
"([012])\1\1\1\1"
dyspnea 200000
obloquy 022222
polecat 000002
sponger 000002
thirsty 022222
Demonstrates that there are no strictly monotonic sequences of length 7
in $w. In fact there are none of length seven or higher.
$ wc $T $w
406712 406712 4158156
/home/ddailey/public_html/moby/mthes/TwoOrMore
35916 35916 332173
/home/ddailey/public_html/words
In the much larger dictionary ($T), there are a couple:
$ egrep ^[a-z]{7}$ $T|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|sort -k2|uniq
-cf1|sort -n|egrep "([012])\1\1\1\1"
2 deglory 222222
2 sponged 000000
16 bailors 022222
19 lifeday 000002
22 avonlea 200000
25 abortus 222220
$ egrep ^[a-z]{7}$ $T|awk '{for (i=1;i<NF;i++) {if
($i>$(i+1))s=s""0;else if ($i<$(i+1))s=s""2;else
s=s""1};{print s" "$0;s="";}} ' FS=""|awk '{print $2,$1}'|egrep
"([012])\1\1\1\1\1"
deglory 222222
egilops 222222
sponged 000000
wronged 000000
and
[truncated?]
More
"standard" (acoustically obvious) rhythms
Counting chars in dict:
$ grep -o . $w|wc -l
296257
$ wc $w
35916 35916 332173 /home/ddailey/public_html/words
$ expr 296257 + 35916
332173
Dividing characters into
Consonants and Vowels
(sort of works for European languages -- not for Chinese)
Vowels:
$ grep -o "[aeiou]" $w|wc -l
114419
$ grep -io "[aeiou]" $w|wc -l
114444
$ grep -o "[AEIOU]" $w|wc -l
25
25 + 114419 = 114444
Consonants
$ grep -o "[bcdfghjklmnpqrstvwxyz]" $w|wc -l
180896
$ grep -oi "[bcdfghjklmnpqrstvwxyz]" $w|wc -l
180944
$ grep -o "[BCDFGHJKLMNPQRSTVWXYZ]" $w|wc -l
48
$ expr 48 + 180896
180944
Together:
$ grep -io "[aeiou]" $w|wc -l
114444
$ grep -oi "[bcdfghjklmnpqrstvwxyz]" $w|wc -l
180944
$ grep -o . $w|wc -l
296257
$ expr 114444 + 180944
295388
Nonalphabetic characters:
$ grep -oi "[^a-z]" $w|wc
869
869 1738
$ grep -oi "[^a-z]" $w|sort|uniq -c
746 -
30 ;
1 .
62 '
30 &
$ expr 746 + 30 + 1 + 62 + 30
869
$ expr 869 + 295388
296257
This shows a partition of the 296257 characters of $w =
/home/ddailey/public_html/words into:
Vowels: 114444
Consonants: 180944
And other: 869
$ wc /home/ddailey/public_html/moby/mthes/SixOrMore
66023 66023 595432
/home/ddailey/public_html/moby/mthes/SixOrMore
$ echo {A..Z} {a..z}|sed s/[aeiouAEIOU\ ]//g
BCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz
$ paste <(head SixOrMore) <( head SixOrMore
|sed
's/[aeiouAEIOU]/A/g;s/[BCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz]/C/g;s/A/V/g')
a V
a- V-
A V
aa VV
aah VVC
aahs VVCC
aardvark
VVCCCVCC
aardwolf
VVCCCVCC
aas VVC
ab VC
$ cat SixOrMore|sed -n '/^....$/s/[aeiouAEIOU]/A/gp'|sed
's/[BCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz]/C/g;s/A/V/g'|sort|uniq
-c|sort -nr
1227 CVCC
662 CVCV
468 CVVC
410 CCVC
150 VCVC
68 VCCV
59 VCCC
49 CCVV
38 VVCC
32 CCCV
18 VCVV
10 VVCV
9 CVVV
3 V'VC
2 CVC-
2 CCV-
1 VVVC
1 'CVC
$ cat SixOrMore|sed -n '/^.....$/s/[aeiouAEIOU]/A/gp'|sed
's/[BCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz]/C/g;s/A/V/g'|sort|uniq
-c|sort -nr
1340 CVCVC
908 CVCCC
721 CCVCC
507 CVCCV
490 CVVCC
303 CCVCV
297 CCVVC
247 VCCVC
133 VCVCC
123 CVVCV
118 VCVCV
107 CVCVV
78 CCCVC
69 VCVVC
45 VVCVC
25 VCCVV
24 CVVVC
21 VCCCV
20 VCCCC
17 CCCCV
12 VVCCC
9 CCCVV
7 VVCCV
5 CV-CV
4 CVC'C
3 VVCVV
3 CVVVV
2 CV'VC
2 CVCC-
1 VVC'C
1 VCVVV
1 VCV'C
1 VCC'C
1 CV-VC
1 CVïCV
1 CVCV-
1 CV'CV
1 CV-CC
1 C-CVC
1 'CCVC
cat SixOrMore|sed -n '/^......$/s/[aeiouAEIOU]/A/gp'|sed
's/[BCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz]/C/g;s/A/V/g'|sort|uniq
-c|sort -nr|head -50
2308 CVCCVC
905 CVCVCC
620 CCVCVC
501 CCVCCC
497 CVVCVC
492 CVCVCV
380 CVCVVC
328 VCCVCC
257 CCVVCC
239 CVCCCV
193 VCCVCV
180 VCVCVC
178 CVVCCC
157 CVCCVV
151 CVCCCC
128 CCVCCV
125 VCCVVC
111 CCCVCC
104 VCCCVC
103 CVVCCV
64 CCVVCV
59 CCCVCV
57 CCCCVC
49 VVCCVC
45 VCVCCC
41 CVVCVV
40 VCVVCC
37 VCVCCV
35 CCCVVC
31 VVCVCC
28 CCVCVV
21 VCVVCV
18 VCVCVV
17 VVCVCV
14 CVVVCC
9 VCCCVV
8 CCCCCV
7 VVCVVC
7 VVCCCC
7 VCCCCV
5 CVCVVV
5 CCCCVV
4 CCVVVC
3 CVVVCV
3 CVCC'C
2 VVCCVV
2 VVCCCV
2 VCCCCC
2 CVVVVC
2 CV-VCC
Seven letters:
$ cat SixOrMore|sed -n '/^.......$/s/[aeiouAEIOU]/A/gp'|sed
's/[BCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz]/C/g;s/A/V/g'|sort|uniq
-c|sort -nr|head -50
1824 CVCCVCC
928 CCVCCVC
821 CVCVCVC
694 CVCCCVC
623 CVCCVCV
546 CVCCVVC
394 CVVCVCC
361 CVVCCVC
360 CCVCVCC
333 VCCVCVC
263 CCVVCVC
231 CVCVCCV
195 CVCVCCC
167 CCVCVCV
166 CVCVVCC
147 VCVCVCC
137 CCVCVVC
136 VCCCVCC
125 VCVCVCV
111 VCVCCVC
111 VCCVCCC
110 CCVCCCV
89 CVCVVCV
88 VCCVVCC
87 CCCVCVC
85 VCCCVCV
85 CVVCVCV
82 VCCVCCV
82 CCVCCCC
78 CVCVCVV
72 CCVVCCC
65 CVVCVVC
62 VCVCVVC
60 VCCCVVC
47 VVCCVCC
44 CCCVCCC
40 CVCVVVC
36 CCCCVCC
35 CVVCCCC
34 VCVVCVC
30 VCCVVCV
28 CCVCCVV
26 VCCCCVC
26 CCVVCCV
25 VVCCCVC
25 CCCVVCC
24 CCCCCVC
22 VVCVCVC
22 VCCVCVV
22 CCCCVVC
Eight letters
$ cat SixOrMore|sed -n '/^........$/s/[aeiouAEIOU]/A/gp'|sed
's/[BCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz]/C/g;s/A/V/g'|sort|uniq
-c|sort -nr|head -50
927 CVCCVCVC
835 CVCVCVCC
742 CCVCCVCC
623 CVCCCVCC
462 CVCVCCVC
422 CVCVCVCV
370 CVCVCVVC
349 CVVCCVCC
332 VCCVCCVC
328 CVCCVCCC
268 VCCVCVCC
261 CCVCCCVC
239 CCVCVCVC
227 CCVVCVCC
192 CVCCVVCC
192 CVCCVCCV
191 CVCCCVCV
182 CVCCCVVC
141 VCCVCVCV
135 VCCCVCVC
132 CVCVVCVC
123 VCVCVCVC
121 VCVCCVCC
120 CVCCCCVC
116 CVVCVCVC
115 CCVCCVVC
111 CCVCCVCV
105 VCCVCVVC
92 CVVCCCVC
90 CCVVCCVC
85 CVVCCVCV
84 CCCVCCVC
77 VCCVVCVC
75 CVVCCVVC
74 VCVCCVCV
67 CVVCVCCC
65 CVCCVVCV
61 VCVCCVVC
60 CCVCVCCC
57 CVCVCCCC
56 CCVCVCCV
52 CVCVVCCV
52 CVCCVCVV
47 CVCVVCCC
43 CVVCVCCV
42 CCCVCVCC
41 VCVCCCVC
38 CCVCVVCC
38 CCCCVCVC
37 CCVVCVCV
Spanish
$echo $s
es.txt
data$pwd
/home/SRUNET/david.dailey/data
Most frequent characters
$cat $s|sed 's/\ .*//;s/./&\n/g'|awk '!/^$/'|sort|uniq -c|sort
-nr|head -50
537718 a
454007 e
353327 r
342698 o
336226 i
313406 s
295433 n
224557 t
215427 l
189358 c
165198 d
148208 m
135614 u
101579 p
82573 b
79228 g
69799 h
52981 v
46424 f
37876 k
30150 y
29973 á
29960 z
25592 í
25280 j
24380 é
17352 ó
14592 w
14034 q
10128 x
4989 ñ
4261 ú
2045 ò
1754 à
1732 ô
1588 â
1441 ï
1170 è
885 ü
721 ì
701 ê
591 ソ
466 ã
438 ö
401 ż
396 ą
358 ç
317 î
309 ä
247 û
$grep ソ $s
ソpor 16
ソest疽 16
ソte 12
ソno 12
ソpuedo 8
ソde 8
ソeres 7
ソes 6
ソqui駭 6
A Google search for ‘ソest疽’ reveals about 5000 hits, including
https://commons.wikimedia.org/wiki/TimedText:The_Million_Ryo_Pot_(1935).webm.ja.srt
Entitled “Japanese subtitles for clip: File:The Million Ryo Pot
(1935).webm” , the page has 1219 entries, many of which appear to be
Spanish with frequent transcription errors: e.g.
725
00:52:24,546 --> 00:52:27,276
Es la segunda casa desde la esquina,
delante de un pozo. No tiene p駻dida.
$cat $s|sed 's/\ .*//;s/./&\n/g'|awk '!/^$/'|sort|uniq -c|sort
-nr|head -50|awk '{print $2}'|tr '\n' ' '
a e r o i s n t l c d m u p b g h v f k y á z í j é ó w q x ñ ú ò à ô â
ï è ü ì ê ソ ã ö ż ą ç î ä û
a$v=[aeoiuáíéóúòàôâïèüìêãöąîäû]
data$c=[rsntlcdmpbghvfkyzjwqxñżç]
Spanish 4:
$awk '{print $1}' $s|sed -n
'/^.\{4\}$/s/[aeoiuáíéóúòàôâïèüìêãöąîäû]/V/gp'|sed
's/[rsntlcdmpbghvfkyzjwqxñżç]/C/g'|sort|uniq -c|sort -nr|head -24
6082 CVCV
3453 CVCC
2066 CVVC
1865 CCVC
1520 VCVC
1251 VCCV
568 CCCV
562 CVVV
506 VCVV
498 CCVV
467 VVCV
441 VCCC
165 VVCC
124 VVVC
62 VVVV
14 ソCVC
13 CVCž
9 CVńV
8 ĺźCV
8 CVëC
6 CVCแ
5 CVýV
5 CVCù
5 CVC
English 4
$cat $e|sed 's/\ .*//;s/./&\n/g'|awk '!/^$/'|sort|uniq -c|sort
-nr|head -50|awk '{print $2}'|tr '\n' ' '
$cat $e|sed 's/\ .*//;s/./&\n/g'|awk '!/^$/'|sort|uniq -c|sort
-nr|head -50|awk '{print $2}'|tr '\n' ' '
e a i r o n s t l u c h d m g p b k y f v w z j x q é ÿ í á ï ä ó è ö ñ
î þ ã а ü о е и ç å à ý ê т
data$ev="e a i o u é ÿ í á ï ä ó è ö î ã а ü о е и å à
ê"
data$ec="r n s t l c h d m g p b k y f v w z j x q ñ þ ç
т"
data$echo $ec|sed 's/\ //g'
rnstlchdmgpbkyfvwzjxqñþçт
data$echo $ev|sed 's/\ //g'
eaiouéÿíáïäóèöîãаüоеиåàê
$awk '{print $1}' $e|sed -n
'/^.\{4\}$/s/[eaiouéÿíáïäóèöîãаüоеиåàê]/V/gp'|sed
's/[rnstlchdmgpbkyfvwzjxqñþçт]/C/g'|sort|uniq -c|sort -nr|head -24
5235 CVCV
5079 CVCC
2704 CCVC
2500 CVVC
1651 VCVC
1269 VCCV
884 VCCC
881 CCCV
568 CCVV
514 CVVV
437 VVCC
420 VVCV
413 VCVV
172 VVVC
51 VVVV
18 CôCV
14 CVCô
13 ηVCC
12 CVšV
12 CVCò
11 CøCV
10 CâCV
9 CVCú
8 žVCV
Note that for four letter words, in both Spanish and English, CVCV is
the top-occuring pattern, while CVCC is second. Note also
that when I used the top fifty characters in English ‘ô’ and ‘ú’
clearly vowels didn’t appear in the top fifty. The above script could
clearly be refined, but it is interesting to note that the pattern CôCV
is slightly more frequent than VCCC or CCCC in this particular
vocabulary of the language. (some of the more frequent occurances:
$grep "^.ô..\ " $e côte 17 (as in Côte d’Azur), môle 14, côté 13, dôme
10, môme 6, cômo 5, côme 5, rôti 4 (as in poulet rôti - wrapped in
bacon, with purée and fennel
(https://www.tripadvisor.co.uk/LocationPhotoDirectLink-g186338-d1388950-i94968576-Cote_Brasserie_Covent_Garden-London_England.html)
), also in familiar appearance: lancôme 3,)
French and German (just for fun):
$wc $g $f
317388 634776 4573651 de.txt
305763 611526 3833939 fr.txt
623151 1246302 8407590 total
$cat $f $g|sed 's/\ .*//;s/./&\n/g'|awk '!/^$/'|sort|uniq
-c|sort -nr|head -60|awk '{print $2}'|tr '\n' ' '
e r n i a s t l o u h c g m d p b f k v é z w y ä ü j q x è ö ê ß ï í â
î ç ô á ž û à ó ì č š å ã ë ο ñ ú œ ę þ ù æ ÿ õ
$echo $fgv
eiasouéyäüèöêïíâîôáûàóìåãëοúœęùæÿõ
$echo $fgc|sed 's/\ //g'
rnstlhcgmdpbfkvzwyjqxßçžčšñþ
$awk '{print $1}' $f|sed -n
'/^.\{4\}$/s/[eiasouéyäüèöêïíâîôáûàóìåãëοúœęùæÿõ]/V/gp'|sed
's/[rnstlhcgmdpbfkvzwyjqxßçžčšñþ]/C/g'|sort|uniq -c|sort -nr|head -24
4184 CVCV
1720 CVCC
1597 CVVC
1171 CVVV
945 CCVC
903 VCVC
864 VVCV
838 VCCV
680 VCVV
553 CCVV
381 VVVC
304 VVVV
283 CCCV
272 VVCC
165 VCCC
5 CVCò
5 CòCV
5 CˆCV
4 CVďC
3 VCCò
3 CVC嶪
3 CVCŕ
3 CVCø
3 CøCV
German
$awk '{print $1}' $g|sed -n
'/^.\{4\}$/s/[eiasouéyäüèöêïíâîôáûàóìåãëοúœęùæÿõ]/V/gp'|sed
's/[rnstlhcgmdpbfkvzwyjqxßçžčšñþ]/C/g'|sort|uniq -c|sort -nr|head -24
2376 CVCV
1793 CVCC
1151 CVVC
729 CCVC
648 CVVV
635 VCVC
498 VCCV
474 VVCV
311 VCVV
291 VVCC
268 CCVV
251 VVVC
176 VCCC
169 VVVV
144 CCCV
4 κVCC
3 ηVCC
2 μVCC
2 ηVVC
2 ηVCV
2 εVCV
2 αVCV
2 αCVV
1 νVVC
Conclusion: It is interesting to note that for these four languages,
the most prevalent forms of Consonant-Vowel rhythms for four letter
words are, first: CVCV and second: CVCC).
English 5
$awk '{print $1}' $e|sed -n
'/^.\{5\}$/s/[eaiouéÿíáïäóèöîãаüоеиåàê]/V/gp'|sed
's/[rnstlchdmgpbkyfvwzjxqñþçт]/C/g'|sort|uniq -c|sort -nr|head -32
10562 CVCVC
8473 CVCCV
4573 CVCCC
3367 CCVCC
2736 CCVCV
2623 CVVCV
2550 VCCVC
2533 CVCVV
2403 CVVCC
1888 VCVCV
1419 CCVVC
1319 CCCVC
1075 VCVCC
583 CVVVC
568 VCVVC
534 VVCVC
512 CCCCV
507 VCCVV
490 VCCCV
337 VCCCC
243 VVCCC
216 VVCCV
214 CCCVV
170 CCVVV
126 VVVCC
109 CVVVV
105 VVCVV
74 VVVCV
67 VCVVV
37 VVVVC
25 VVVVV
17 CVυCC
Spanish 5
$awk '{print $1}' $s|sed -n
'/^.\{5\}$/s/[aeoiuáíéóúòàôâïèüìêãöąîäû]/V/gp'|sed
's/[rsntlcdmpbghvfkyzjwqxñżç]/C/g'|sort|uniq -c|sort -nr|head -32
10524 CVCVC
8301 CVCCV
3180 CVCVV
2962 CVVCV
2911 VCVCV
2743 CCVCV
2540 CVCCC
2080 VCCVC
1702 CCVCC
1247 CVVCC
904 CCVVC
657 CCCVC
578 CVVVC
577 VCCVV
555 VCVVC
451 VCVCC
437 VVCVC
381 VCCCV
339 VVCCV
272 CCCCV
248 CVVVV
149 VVVCV
136 VVCVV
133 CCVVV
132 CCCVV
117 VCCCC
106 VCVVV
77 VVCCC
48 VVVVC
37 VVVVV
29 VVVCC
13 ソCVCV
Note that for five letter words, in both Spanish and English, CVCVC is
the top-occuring pattern, while CVCCV is second.
Spanish 6
$awk '{print $1}' $s|sed -n
'/^.\{6\}$/s/[aeoiuáíéóúòàôâïèüìêãöąîäû]/V/gp'|sed
's/[rsntlcdmpbghvfkyzjwqxñżç]/C/g'|sort|uniq -c|sort -nr|head -32
13257 CVCCVC
13213 CVCVCV
3243 CVCVVC
3210 CCVCVC
3127 CVVCVC
2832 CVCCVV
2777 VCCVCV
2769 CVCVCC
2394 VCVCVC
2038 CCVCCV
1994 CVCCCV
1699 CVVCCV
1671 VCVCCV
910 CCVCCC
780 CCVVCV
767 CCVCVV
750 VCVCVV
730 VCCVCC
676 CVVCVV
647 VCCCVC
605 CVCCCC
596 VCCVVC
579 VCVVCV
509 CCVVCC
468 CVCVVV
432 CCCVCV
414 CVVVCV
396 VVCVCV
375 CCCVCC
343 CVVCCC
338 CCCCVC
270 VVCCVC
English 6
$awk '{print $1}' $e|sed -n
'/^.\{6\}$/s/[eaiouéÿíáïäóèöîãаüоеиåàê]/V/gp'|sed
's/[rnstlchdmgpbkyfvwzjxqñþçт]/C/g'|sort|uniq -c|sort -nr|head -32
15464 CVCCVC
8722 CVCVCV
4935 CVCVCC
3706 CCVCVC
3489 CVVCVC
2623 CVCCVV
2578 CVCCCV
2559 CVCVVC
2333 CCVCCV
1980 CCVCCC
1841 VCCVCC
1696 VCCVCV
1602 CVCCCC
1560 CVVCCV
1454 VCVCVC
1107 CCVVCC
981 CCCVCC
968 VCCCVC
943 CVVCCC
915 VCVCCV
843 CCCCVC
777 CVVCVV
737 CCVVCV
698 VCCVVC
653 CCCVCV
635 CCVCVV
420 VVCCVC
396 CCCVVC
366 VCVCVV
319 VCVCCC
317 VCVVCV
280 VVCVCC
Note that for six letter words, in both Spanish and English,
CVCCVC is the top-occuring pattern, while CVCVCV is
second. However, note some disagreement in lower ranked
patterns:
English (4935 CVCVCC)3 > (2559 CVCVVC)8
Spanish (2769 CVCVCC)8 < (3243 CVCVVC)3
Consononant Vowel rhythms in
English, Spanish, French and German vocabulary
English 7
$awk '{print $1}' $e|sed -n
'/^.\{7\}$/s/[eaiouéÿíáïäóèöîãаüоеиåàê]/V/gp'|sed
's/[rnstlchdmgpbkyfvwzjxqñþçт]/C/g'|sort|uniq -c|sort -nr|head -32
8710 CVCCVCC
6206 CVCCVCV
6140 CVCVCVC
5013 CVCCCVC
4789 CCVCCVC
4524 CVCVCCV
3145 CVCCVVC
2297 CVVCCVC
1789 CVVCVCC
1742 CCVCVCV
1707 CCVCVCC
1694 VCCVCVC
1463 CVCVCVV
1288 CCVVCVC
1242 CVCVVCV
1152 CVCVCCC
1091 VCVCVCV
1016 CVVCVCV
869 VCVCCVC
839 VCCVCCV
824 CVCVVCC
753 CCVCVVC
737 VCCCVCC
716 CCVCCCV
676 CVVCVVC
669 CCCVCVC
589 CVCCCCC
586 CCVCCVV
578 CCVCCCC
576 VCVCVCC
557 CVCCCVV
556 CCCCVCC
Spanish 7
$awk '{print $1}' $s|sed -n
'/^.\{7\}$/s/[aeoiuáíéóúòàôâïèüìêãöąîäû]/V/gp'|sed
's/[rsntlcdmpbghvfkyzjwqxñżç]/C/g'|sort|uniq -c|sort -nr|head -32
10517 CVCVCVC
9802 CVCCVCV
7033 CVCVCCV
4554 CVCCVCC
3273 CVCCCVC
3047 CCVCCVC
2997 VCVCVCV
2932 CVCCVVC
2729 CCVCVCV
2579 VCCVCVC
2540 CVCVCVV
2328 CVCVVCV
1860 CVVCVCV
1805 CVVCCVC
1755 VCCVCCV
1225 VCVCCVC
845 CCVVCVC
763 VCCVCVV
762 CCVCVCC
741 CCVCVVC
735 CVVCVCC
713 VCVCVVC
642 VCCCVCV
608 VCCVVCV
564 CVVCVVC
512 CVCVCCC
502 CCVCCVV
469 CCVCCCV
447 VCVVCVC
442 CVCCCVV
439 CVCVVVC
380 CCCVCVC
Let’s also look at French and German:
French 7
$awk '{print $1}' $f|sed -n
'/^.\{7\}$/s/[eiasouéyäüèöêïíâîôáûàóìåãëοúœęùæÿõ]/V/gp'|sed
's/[rnstlhcgmdpbfkvzwyjqxßçžčšñþ]/C/g'|sort|uniq -c|sort -nr|head -24
3774 CVCCVCV
2838 CVCVCCV
2692 CVCVCVV
2300 CVCVCVC
1876 CVCCVCC
1874 CVCVVCV
1486 CVCCVVC
1276 CVVCVCV
1136 CVCCVVV
1080 CVCCCVC
1017 VCVCVCV
1013 CCVCVCV
931 VCCVCVV
915 CVVCCVC
898 CCVCCVC
893 VCCVCCV
804 CVVCCVV
754 CVCVVVV
680 VCVCCVC
667 CCVCCVV
663 CVCCCVV
642 VCCVCVC
630 CVVCVVC
611 CVVCVCC
German 7
$awk '{print $1}' $g|sed -n
'/^.\{7\}$/s/[eiasouéyäüèöêïíâîôáûàóìåãëοúœęùæÿõ]/V/gp'|sed
's/[rnstlhcgmdpbfkvzwyjqxßçžčšñþ]/C/g'|sort|uniq -c|sort -nr|head -24
2214 CVCCVCV
2166 CVCCVCC
1577 CVCVCVC
1304 CVCCCVC
1234 CVCVCCV
967 CCVCCVC
911 CVCCVVC
846 CVVCCVC
762 CVCVCVV
686 VCCVCVC
665 VCVCCVC
650 CVVCVCV
642 CVCVVCV
620 CVVCVCC
565 CVCCVVV
564 VCCVCCV
461 CVCVCCC
453 CCVVCVC
393 VCVCVCV
393 CVCVVCC
390 VCCCVCC
376 CVVVCVC
367 CCVCVCV
354 CVCCCVV
Note that English ( 8710 CVCCVCC)1 > (6140 CVCVCVC)3
While Spanish (4554 CVCCVCC)4 < (10517 CVCVCVC)1
In French (1876 CVCCVCC) 5 < (2300
CVCVCVC)4
And in German (2166 CVCCVCC)2 > (1577 CVCVCVC) 3
Examples:
CVCrhythm
English Spanish
CVCCVCC
forward/selling raymond/bistecs
CVCCVCV
destiny/lottery soldado/cerrado
CVCVCVC
related/titanic sigamos/pedimos
CVCCCVC
matches/seltzer mostrar/manchas
CCVCCVC
stalled/bracket francos/prestar
CVCVCCV
bizarre/syringe podréis/cambios
CVCCVVC
passion/penguin viernes/sientas
CVVCCVC
neither/measles cierren/cuernos
VCVCVCV
ability/episode apetece/editado
CVCVCVV
someday/referee refería/delicia
CVCVVCV
genuine/release líquido/valiosa
CVVCVCV
sausage/seizure realeza/quemado
CVCCVVV
kumbaya/hawkeye desmayó/turquía
CCVCVCV
closely/precise llamaba/trasera
VCCVCVV
amnesia/antique odiaría/acuario
Seven letter sequences: comparisons of consonant-vowel rhythms across
English, Spanish, French and German:
Relative frequency for most popular CVC sequences relative to the total
number sampled.
The above table involved first choosing the eight most frequently
occurring sequences in English, and then “bootstrapping” outward so
that each language’s highest frequency entries were included.
CVCCVCC
CVCCVCV
CVCVCVC
CVCCCVC
CCVCCVC
CVCVCCV
CVCCVVC
CVVCCVC
VCVCVCV
CVCVCVV
CVCVVCV
CVVCVCV
CVCCVVV
CCVCVCV VCCVCVV
English
8710 6206
6140 5013
4789 4524
3145 2297
1454 1463
1241 1016
222 1742 366
Spanish
4554 9802
10517 3273
3047 7033
2932 1805
2997 2540
2328 1860
310 2729 734
French 1876
3774 2309
1080 1486
2838 1486
915 1017
2692 1874
1276 1136
1013 931
German 2166
2214 1577
1304 967
1234 911
846 393
762 642
650 565
367 704
Specifically, if as we see above,In order to “get to” the eight highest
sequences for English (CVVCCVC at 2297 in English but only 1805 in
Spanish) the following Spanish sequences were higher in frequency than
the Spanish value of this pattern: 1805. Namely, the sequences
(VCVCVCV:2997, VCVCVCV:2540, CVCVCVV:2328, CVCVVCV: 1860) all had to be
considered before inclusion of CVVCCVC could be entertained. This
method was extended until all four languages had represented in the
table, their top eight values. This required the addition of
seven more columns as can be seen.
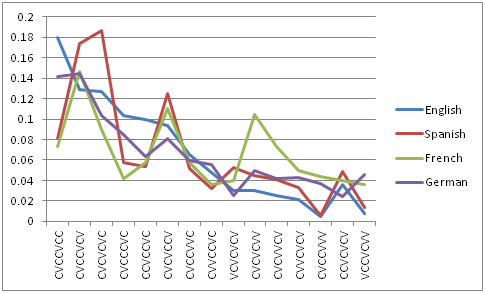
Spanish 9
$awk '{print $1}' $s|sed -n
'/^.\{9\}$/s/[aeoiuáíéóúòàôâïèüìêãöąîäû]/V/gp'|sed
's/[rsntlcdmpbghvfkyzjwqxñżç]/C/g'|sort|uniq -c|sort -nr|head -32
6006 CVCVCVCVC
5452 CVCCVCVCV
4164 CVCVCCVCV
3651 CVCVCVCCV
3380 CVCCVCCVC
2702 VCCVCVCVC
1961 VCCVCCVCV
1868 VCCVCVCCV
1808 CVCCVCVVC
1420 CCVCVCVCV
1355 VCVCCVCVC
1297 CVCCVVCVC
1218 CVCCCVCVC
1136 VCVCVCVCV
1039 CVCVCVCVV
1002 CVCVCCVVC
989 CVCVCVVCV
946 CVCCVVCCV
939 CCVCCVCVC
933 VCVCCVCCV
741 CCVCVCCVC
740 VCCCVCVCV
734 CVCCCVCCV
705 CVCCVCVCC
644 CVVCVCVCV
627 VCVCVCCVC
612 CVCVVCVCV
605 CCVCCVCCV
602 CVVCCVCVC
551 CVCVVCCVC
543 CVCVCCVCC
533 CCVCVCVVC
English 9
$awk '{print $1}' $e|sed -n
'/^.\{9\}$/s/[eaiouéÿíáïäóèöîãаüоеиåàê]/V/gp'|sed
's/[rnstlchdmgpbkyfvwzjxqñþçт]/C/g'|sort|uniq -c|sort -nr|head -32
3240 CVCCVCCVC
2342 CVCCVCVCV
2295 CVCCVCVCC
1787 CVCVCVCVC
1571 CVCVCCVCC
1454 CVCVCCVCV
1428 CVCVCVCCV
1218 CVCCCVCVC
1156 CVCCVCVVC
1047 CCVCCCVCC
921 CCVCCVCVC
884 CVCCCCVCC
859 VCCVCCVCC
738 CVCCCVCCC
733 CCVCVCVCV
715 CCVCVCVCC
712 CCVCVCCVC
660 CVCVCCVVC
616 CVCCVVCVC
612 VCCVCVCVC
600 CVCVCCCVC
558 CVCCCVCCV
525 CVCVCVCCC
517 CCVVCCVCC
512 CVVCCCVCC
501 VCCVCCVCV
494 CVVCCVCVC
482 CVCCVCCCV
482 CCVCCVCCV
473 CVCCCVVCC
460 CCVCCVCCC
424 CVCCVCCCC
English 9 (from different dictionary )
$ cat SixOrMore|sed -n '/^.\{9\}$/s/[aeiouAEIOU]/A/gp'|sed
's/[BCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz]/C/g;s/A/V/g'|sort|uniq
-c|sort -nr|head -32
640 CVCCVCVCC
403 CVCCVCCVC
381 CVCVCCVCC
322 CVCCVCVCV
314 CVCVCVCVC
314 CVCCVCVVC
267 VCCVCCVCC
200 CCVCCCVCC
184 CCVCVCVCC
170 CVCVCCVCV
164 CCVCCVCVC
156 VCCVCVCVC
151 CVCCCVCVC
130 CVCCCCVCC
129 CVCVCVCCC
124 CVCVCCVVC
122 VCCVCCVCV
119 CCVVCCVCC
110 CVCCVVCVC
106 CVVCCCVCC
103 CVCVVCVCC
98 CVCVCVCCV
98 CCVCVCCVC
97 CCVCVCVVC
90 CVVCVCVCC
88 VCCVCCVVC
87 CCVCVCVCV
85 VCVCVCVCC
82 VCCCVCVCC
82 CVCVCVVCC
80 VCCCVCCVC
78 CVCCCVCCC
Note that English (3240 CVCCVCCVC)1 > (1787 CVCVCVCVC)4
(generally consistent across both methods)
While Spanish (3380 CVCCVCCVC)5 < (6006 CVCVCVCVC)1