



6a.1. Internet Context
If the Web is the car you drive to work, a movie, a club, or a friend's house, the Internet is the transportation system that lets you get there. And, like the highway, rail, water and air systems, it supports far more than just those things you personally use. The Internet is the substrate upon which the Web, and a lot of other services, are built.
How you connect to the Internet is a subject we will discuss in the sections on networks. For now, we will just assume you have a connection.
In the previous sections we mentioned the Internet as though it was obvious what it was. (Indeed, we have extensively used the Internet for the course.) Just as we delved into computers to understand them better, here we take a closer look at the Internet.
What is the Internet? [src]

US Interstate Highway System (1976)
Five public domain images
Note that personal & mass transportation, shipping, etc. all use the same underlying highway system




The Internet is a global system of interconnected computer networks that use the standard Internet Protocol Suite (TCP/IP) to serve approx. 3.2 billion users worldwide. It is a network of networks that consists of millions of private, public, academic, business, and government networks, of local to global scope, that are linked by a broad array of electronic (wired), wireless and optical networking technologies. The Internet carries a vast range of information resources and services, such as the inter-linked hypertext documents of the World Wide Web (WWW) and the infrastructure to support electronic mail.
Most traditional communications media, including telephone, music, film, and television, have been reshaped or redefined by the Internet, giving birth to new services such as Voice over Internet Protocol (VoIP) and IPTV. Newspaper, book and other print publishing are adapting to Web site technology, or are reshaped into blogging and web feeds. The Internet has enabled or accelerated new forms of human interactions through instant messaging, Internet forums, and social networking. Online shopping has boomed both for major retail outlets and small artisans and traders. Business-to-business and financial services on the Internet affect supply chains across entire industries.

Number of Internet users in 2012
By Jeff Ogden (W163) [CC BY-SA 3.0], via Wikimedia Commons

Internet users per 100 inhabitants
By Jeff Ogden (W163) (Own work) [CC BY-SA 3.0], via Wikimedia Commons
History
The origins of the Internet reach back to research of the 1960s, commissioned by the United States government (military) in collaboration with private commercial interests to build robust, fault-tolerant, and distributed computer networks. The funding of a new U.S. backbone by the National Science Foundation in the 1980s, as well as private funding for other commercial backbones, led to worldwide participation in the development of new networking technologies, and the merger of many networks. The commercialization of what was, by the 1990s, an international network resulted in its popularization and incorporation into virtually every aspect of modern human life. As of 2016, almost half the of Earth's population used the services of the Internet.

Symbolic representation of the Arpanet as of September 1974
public domain image
NSFNET Backbone Map 1992
Source: Merit Network, Inc. Uploaded by W163. Creative Commons Attribution-ShareAlike 3.0 License
Who's In Charge?
The Internet has no centralized governance in either technological implementation or policies for access and usage; each constituent network sets its own standards. Only the over reaching definitions of the two principal name spaces in the Internet, the Internet Protocol address space and the Domain Name System, are directed by a maintainer organization, the Internet Corporation for Assigned Names and Numbers (ICANN). The technical underpinning and standardization of the core protocols (IPv4 and IPv6) is an activity of the Internet Engineering Task Force (IETF), a non-profit organization of loosely affiliated international participants that anyone may associate with by contributing technical expertise. On 16 November 2005, the World Summit on the Information Society, held in Tunis, established the Internet Governance Forum (IGF) to discuss Internet-related issues.
Unlike the US, in some countries the government is in complete control of their Internet infrastructure. Even in the US, the government has sought the power to shut down the Internet in emergencies.
A later sidebar on social networks and social change is relevant here.
While any number of inventions and "advancements" in western society have been blamed on the military-industrial complex, there is no doubt that the foundations of the Internet were fundamentally based in the support of (war time) communications.
The Internet has become a way for people from all over the world (to varying degrees) to communicate with one another, sometimes leading to the downfall of repressive regimes.
Secretary of State Clinton Speaks on Internet's Role in Mideast Unrest, National Journal, February 15, 2011. (Includes policy discussion on Internet freedom & control.)
 shutting off internet
internet censorship
obama internet
shutting off internet
internet censorship
obama internet
Communication
The initial goal of the Internet effort – it wasn't called that yet – was to find ways to address the US military's concern about survivability of their communications networks and, as a first step, to interconnect their computers. The Internet has always been about communication and it still is — Web browsing, email, blogs, videos, etc. Many currently popular applications had their roots in the early Internet. Some, like email, haven't even changed much.
There are two basic models for communicating (files, images, sound, voice, etc.) over the Internet. The first is circuit switching. It is based on the old telephone system: once a connection is made, you have a reliable, semi-permanent "pipeline" to send your data through and can reasonably expect it will all be delivered correctly. The other is packet switching. In this model, your data is broken up into a series of packets that are sent independently through the Internet and reassembled at the other end. (This is a bit like sending a long letter through the postal service using a series of numbered postcards.)
Both methods are still used extensively. The choice (made by programmers) is based on several factors, including: Can we can afford to lose a bit of data, as in most audio and video connections, or must every bit arrive exactly as sent? Does the time necessary to set up a switched circuit matter? Do we gain by allowing individual packets to be routed independently, perhaps around a congested part of the network?
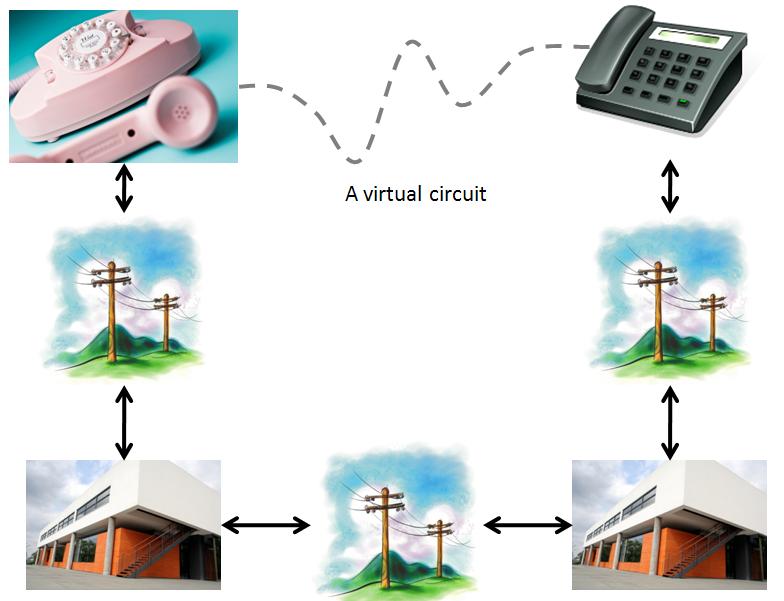
Virtual Circuit switching metaphor using phone system – By Paul Mullins: constructed
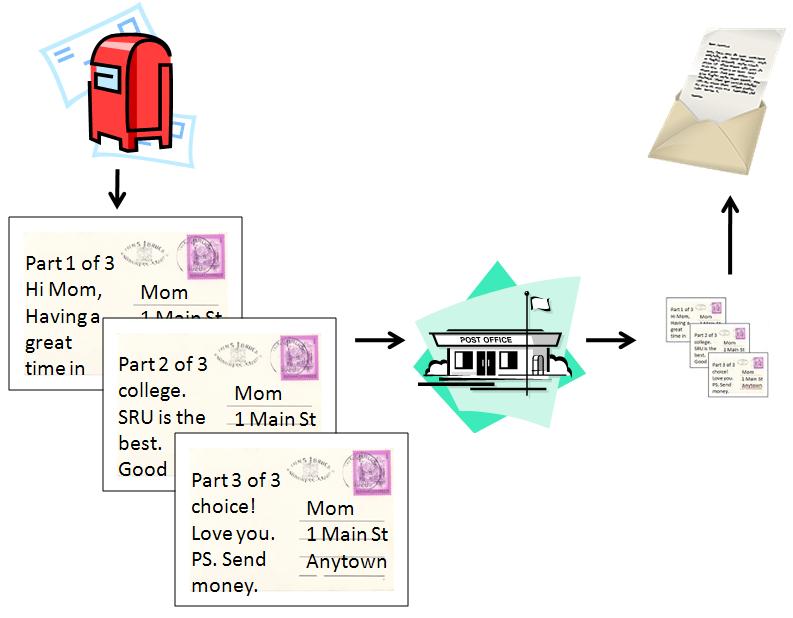
A packet switched message metaphor using postcards – By Paul Mullins: constructed
Much of the mechanics of networking has to do with making connections, sending & receiving data, checking for errors, maintaining privacy, etc. Like the old phone system, where you created a "circuit" by simply dialing a number, we will ignore the "mechanics" and look at it more abstractly. We gain some insight, however, from noting that parts of our data might be lost or corrupted in transit. In some cases, like file transfers, this is unacceptable and the missing (or damaged) data is requested automatically. In other case, like streaming audio, it might be ignored – both by the system and by you.
Also, both circuit and packet switching likely involve multiple computers to receive and forward data for us, i.e., there are intermediate nodes (computers) along the path. Since most data is not encrypted (for privacy), this means that "bad guys" may spy on, or in some cases modify, data as it is sent from one end of the path to the other. Most users worry little more about this than they would about having their telephone wire tapped, i.e., they don't. Not necessarily a good choice when you are sending credit card information and any 13 year old hacker (or "somebody sitting on their bed that weighs 400 hundred pounds") can intercept it.
Peer-to-Peer v. Client-Server [src1] [src2]
The client-server model of computing is a distributed application structure that partitions tasks or workloads between the providers of a resource or service, called servers, and service requesters, called clients. Generally clients and servers communicate over a computer network on separate hardware, but both client and server may reside in the same system. A server machine is a host that is running one or more server programs which share their resources with clients. A client does not share any of its resources, but requests a server's content or service function. Clients therefore initiate communication sessions with servers which await incoming requests. This model matches traditional web browsing in which the client (your browser) requests a web page from some web site (the server). The browser then displays whatever the server sends back as a result.

#171 BitTorrent Unscrambled

Client-Server Model
By Bp2010.hprastiawan (Own work) [CC-BY-SA-3.0], via Wikimedia Commons
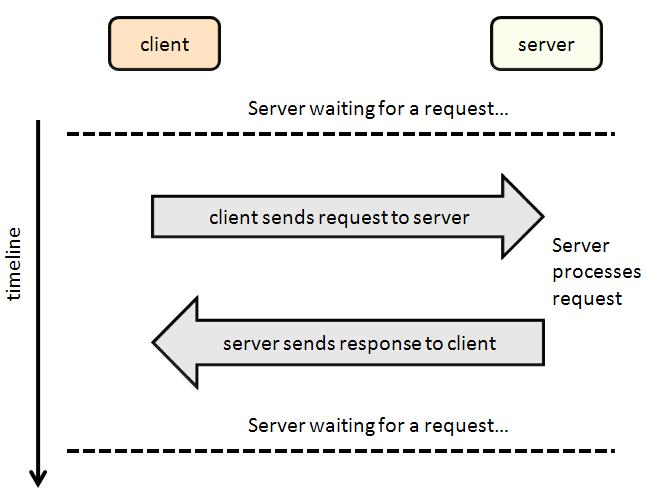
Client-Server process
By Paul Mullins: constructed
Peer-to-peer (P2P) computing or networking is a distributed application architecture that partitions tasks or workloads between peers. Peers are equally privileged, equally powerful participants in the application. They are said to form a peer-to-peer network of nodes.
Peers make a portion of their resources, such as processing power, disk storage or network bandwidth, directly available to other network participants, without the need for central coordination by servers or stable hosts. Peers are both suppliers and consumers of resources, in contrast to the traditional client-server model where only servers supply, and clients consume.
The peer-to-peer application structure was popularized by file sharing systems like Napster and BitTorrent. However, in most home networks, all the computers are peers – no one computer is in charge.

P2P network file sharing. File originates from server, but subsequent sharing is direct from client to client.
By P2ptv.PNG:Soumyasch at en.wikipediaderivative work: Comte0 (P2ptv.PNG) [CC-BY-SA-3.0 or GFDL], from Wikimedia Commons
Protocols
Consider requesting a web page. You type in a web URL (or click on a link). Your browser, a software application, sends a request to a web server, another software application, that then retrieves the information requested and sends it back to your browser for display. Both the request and the response likely travel through many intermediate nodes. For the server to understand the request, or for your browser (the client) to understand the reply, the message(s) must be sent in a very formal way. That is, you have to ask for the file in a way the server program understands. The rules for communicating are called a protocol. In the case of WWW traffic it is the HyperText Transfer Protocol (HTTP).
Your computer takes care of sending the page request message using TCP (Transmission Control Protocol) creating a circuit-like connection to the receiver. At the other end, the receiving host (web server) "hears" the request and dismantles the connection, then delivers the request to the web server application program. This process is reversed for the reply, a copy of the requested page, sent from the server back to you (the client) to be displayed.
For applications that use the packet-oriented communication model, TCP is replaced by UDP (User Datagram Protocol). These actions, and the protocol used, are invisible to you, the user.

Web Browsing
By GNOME developers team (Own work) [GPL, GFDL or CC-BY-SA-3.0-2.5-2.0-1.0], via Wikimedia Commons
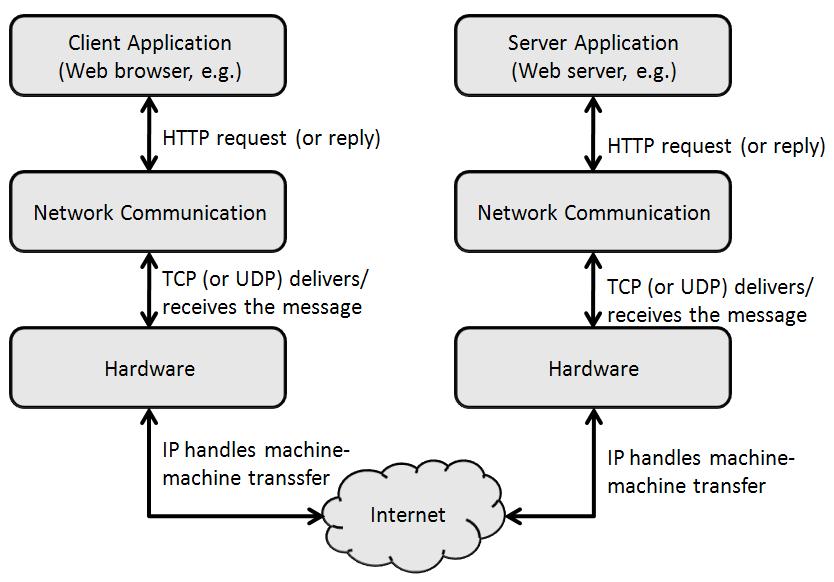
Layered Protocols for a Web request
By Paul Mullins: constructed
At a deeper level, your computer's hardware is talking to another computer's hardware (along with any intermediate nodes). The machines use IP (Internet Protocol) to talk to one another. Most applications we use on the Internet rely on TCP/IP as the underlying communication mechanism. Streaming media, like Voice over Internet (Skype) use the UDP (packet) connections. It is in that sense that the Web is built upon the Internet, as are many other applications you are familiar with.
Some common protocols include:
- HTTP (HyperText Transfer Protocol) – supports WWW communication
- SMTP (Simple Mail Transfer Protocol) – supports email
- FTP (File Transfer Protocol) – supports reliable transfer of files
- POP3 (Post Office Protocol) – supports web-based email clients
- VoIP (Voice over Internet Protocol) – supports Internet telephony
Networks
The original networks were small. They connected computers in one location, such as within a lab or building or perhaps a campus. These are called local area networks (LANs) in reference both to its size and that it was controlled by a local entity (a university or business). These are the kinds of networks we will focus on in the last module.

LAN with one server
public domain image
A somewhat larger network, perhaps encompassing a city, is a metropolitan area network (MAN) and larger still, a wide area network (WAN). Your smartphone is connected to a WAN, provided by your phone service provider. Your PC or laptop is generally connected to a LAN. (A Wi-Fi hotspot is just a wireless LAN.)
Connecting two or more networks together creates an internet, along with problems concerning how to route messages appropriately. (Hence, the device that connects networks is called a router.) A home network is a LAN that you administer, often connected to the Internet via a (wireless) router. Note that the world-wide conglomeration of networks is not just an internet, it is the Internet.
An intranet is a network that is meant to allow local communication only. Many businesses have an intranet for employees to communicate that excludes everyone else on the Internet. An extranet is used (by businesses) to allow controlled access to the public to select information on their (otherwise private) network.

Three LANs in an internet
public domain image
In e-commerce, there can be business-to-business (B2B), business-to-consumer (B2C or on-line retailing) and consumer-to-consumer (C2C) communications over the Internet. Especially when money or sensitive information is exchanged, the communications are apt to be secured by some form of communications security mechanism. Intranets and extranets can be securely superimposed onto the Internet using secure Virtual Private Network (VPN) technology, allowing no access to general Internet users or even node administrators. Most e-commerce transactions use a secure form of HTTP, called HTTPS.[src]
A cloud is a collection of servers, perhaps in multiple locations, that act collectively to provide services. Cloud computing refers to the use of and access to multiple server-based computational resources via a network. Cloud users may access the server resources using a computer, netbook, pad computer, smart phone, or other device. In cloud computing, applications (such as Google docs or gmail) are provided and managed by the cloud server and data is also stored remotely in the cloud configuration. Users do not download and install applications on their own device or computer; all processing and storage is maintained by the cloud server. The on-line services may be offered from a cloud provider or by a private organization.[src]
Technically, both Google docs and gmail are Web apps, not cloud apps, because they require the user to be online when the app is being used. Whereas cloud apps allow the user to download relevant data to the local system for use offline — see the discussion in module 5-03. Cloud apps were not named because they are virtually all for enterprises at this time. According to IBM, the most common uses you are likely to have for the cloud has to do with file storage, backup, and disaster recovery.

Cloud Computing
public domain image
Google Drive | Hands-on Review
Top Five Dropbox Tips and Tricks
#216 Computing in the Cloud
Addressing
For web browsing, we refer to specific sites as a web address. Technically, this address is called a Uniform Resource Locator (URL). It specifies where a known resource is available and the mechanism for retrieving it. That is, it identifies a particular host computer and the protocol to be used to communicate with it.
Individual hosts are specified using a hierarchical naming system starting with a top-level domain. (Kind of like the full pathname of a file on your computer, but listed from right to left.) When directing a browser to the home page of SRU, you specify first the protocol (HTTP://), then the particular host machine (WWW is used by most as the name of their web server), then the institution name (SRU), then the domain (EDU): HTTP://WWW.SRU.EDU
(All major web browsers now assume HTTP:// and don't make you type it in.)
Like a file pathname, longer host names are possible. In addition, you may specify a particular file or directory on a web site by adding the file pathname at the end.
http://cs.sru.edu/~mullins/index.html
refers to a specific file in a specific directory on the host called "CS" that is part of SRU.EDU. Note that not all web servers are called "www" and, although capitalization does not matter for the hostname, you must match the file path name exactly.
For email, an Internet address consists of a user ID, followed by '@', followed by the host that handles email for that user ID: "notReal@gmail.com". Here, the user name may require proper capitalization, the host name does not.
Pet Peeve – homonyms for "site"
I knew I had to cite that site. What a sight it was.- site
- A location, as in a particular web page
- cite
- To quote, as in a reference in a paper
- sight
- To view or see, as in your visual perception of a web page
Your English Prof will expect you to know this.
The most common version of IP now, IPv4, provides for approximately 4.3 billion addresses, but we are running out. IPv6 allows for vastly more addresses. This change should be transparent to you as a user, but is currently a major technical issue in Internet.
Actually host names in the Internet are specified by their IP address, a series of hexadecimal numbers. Like phone numbers, they uniquely specify one particular machine (or phone) in the world. When we type in a URL, the system automatically look up the actual numeric address and substitutes that for us. This as a bit like calling someone by selecting their name in your telephone's contact list – the associated number is dialed automatically.
